Answer the question
In order to leave comments, you need to log in
How to parallelize a Java application computationally across multiple machines?
Given:
Some computational (not a web!) application on bare Java SE 8, consuming about 500 GB of RAM and a solid part of the Intel Xeon E5-2 *** resources in the process and having something like this, God forgive me, structure:
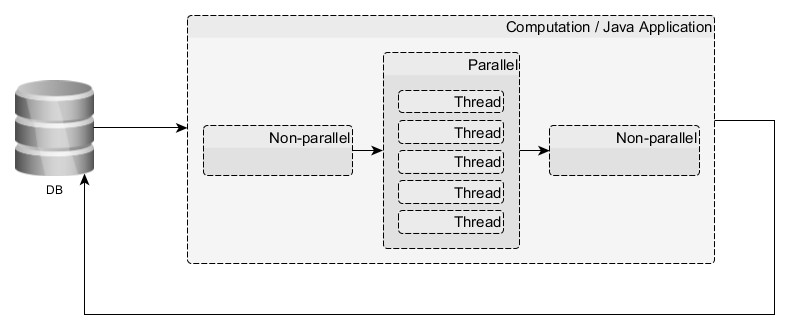
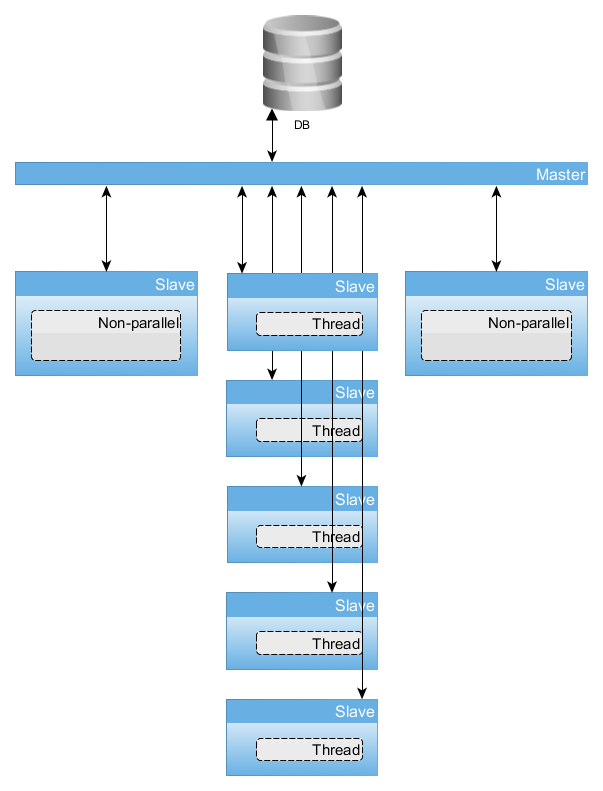
Answer the question
In order to leave comments, you need to log in
I would just use Spark or Ignite so as not to reinvent the wheel.
Of course, I did not come across in practice, but I read a lot about solving such problems and here are a couple of thoughts:
1) If everything is in the database, then why not start paralleling from it. Let's say in a database (possibly a separate one) to mark who took the data for themselves, then the nodes cling to the database, take a bunch of data and mark that they are already in work, i.e. node 2 will not take data that is already on node 1. This is one of the simple solutions in the forehead.
2) All subsequent implementations are in libraries, gridgain , regular RMI, Apache Ignite, Apache River.
Alternatively, use AKKA. It is available for both rock and Java. It's quite easy to "connect multiple machines". But actually parallelization, transferring the application to another concept (asynchronous messaging instead of a direct call) - this will have to break your head.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question