Answer the question
In order to leave comments, you need to log in
How to optimize scraper speed?
There is a scraper running through aiohttp. Data processing and sending goes on a neighboring thread
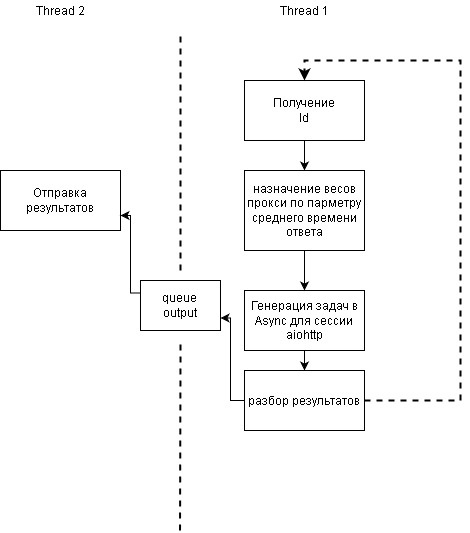
def loop(ids_chunks):
for i in ids_chunks:
# Start Parsing
tic = time.perf_counter()
results, proxy_analize = self.loop.run_until_complete(self.requests_new_items(i, self.proxy_list, self.weight_dict))
toc = time.perf_counter()
print(f"request take {toc - tic:0.4f} seconds,"
f" full amount of requests={ids_amount * len(available)}"
f", ids_chunks amount of requests{len(i) * len(available)}")
print("analize")
self.analize(results, self.extend_id, self.proxy_list) # take less then second
del results
self.proxy_balancer(proxy_analize, self.weight_dict)
async def requests_new_items(self, ids, param_proxy_list, weight_dict):
connector = aiohttp.TCPConnector(limit=self.tcp_speed,
force_close=True) # self.tcp_speed) # One time connection limit
client_timeout = aiohttp.ClientTimeout(connect=9, total=12) # зависит от размера входящего чанка
len_of_requests = int(str(len(ids) * len(available))) # amount of requests
proxy_optimize = random.choices([i for i in weight_dict.keys() if i in param_proxy_list],
[v for k, v in weight_dict.items() if k in param_proxy_list],
k=len_of_proxy) # weights choices of proxy for each request
async with aiohttp.ClientSession(connector=connector, timeout=client_timeout) as session:
responce_list = await asyncio.gather(*[self.fetch_one(session, proxy_optimize[current_index], id_of_url,
current_index // len(ids)) for
current_index, id_of_url in enumerate(ids * len(available))])
del proxy_optimize
new_item_or_except = [i for i in responce_list if i[0]]
proxy_analize = [(i[1], i[2]) for i in responce_list if not i[0]] # list for calculate average responce time
return new_item_or_except, proxy_analize
async def fetch_one(self, session, proxy, id_of_url, available_id):
try:
await_time = time.perf_counter() # for calculate average responce time
result = await session.head(f"{areas_of_lock[available_id]}/{id_of_url}",
proxy=f"http://{proxy}",
headers=headers_const)
if not result.status == 404:
return (id_of_url, result.status, area_id)
return (None, proxy, time.perf_counter() - await_time)
except Exception as err:
print(err)
return (id_of_url, proxy)
def proxy_balancer(self, proxy_responce, weight_dict):
weight_dict_average = dict() # dict with full responce time for each proxy
for i in proxy_responce:
if not weight_dict_average.get(i[0]):
weight_dict_average[i[0]] = i[1]
weight_dict_average[i[0] + '_count'] = 1
else:
weight_dict_average[i[0]] += i[1]
weight_dict_average[i[0] + '_count'] += 1
weight_dict_average_values = dict() # 1/(avarage value)
for i in weight_dict.keys():
if weight_dict_average.get(i):
weight_dict_average_values[i] = 1 / (weight_dict_average[i] / weight_dict_average[i + '_count'])
full_avarage_time = sum(weight_dict_average_values.values())
# calculate weights for cohice
for i in weight_dict.keys():
if weight_dict_average_values.get(i):
weight_dict[i] = weight_dict_average_values[i] / full_avarage_timeAnswer the question
In order to leave comments, you need to log in
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question