Answer the question
In order to leave comments, you need to log in
How to optimize for a huge table in a SQL Server database?
Good day to all.
There are 3 tables: 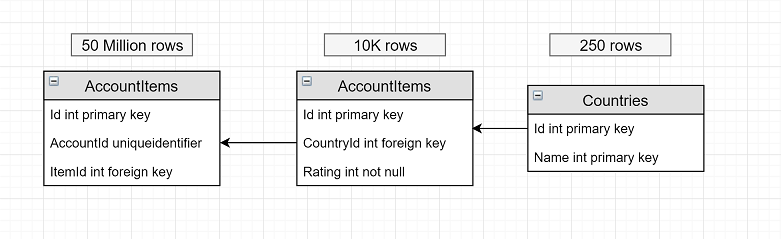
The AccountItems table stores the items of a specific user (AccountId). One user may have several identical items, that is, the AccountItems table may contain duplicates.
The table is very large and grows every day. Every second, the data in the AccountItems table is changed (added, updated, deleted).
We need to optimize the following things:
WITH groups as
(
select AI.*, ROW_NUMBER() OVER (PARTITION BY AI.ItemId ORDER BY AI.ItemId DESC) as row_num from AccountItems AI
inner join Items I on I.Id = AI.ItemIdId
inner join Countries C on C.Id = I.CounrtyId
where AccountId = @uniqueId
and I.Rating = @rating
and Name = @name
)
select groups.* from groups
inner join Items I on I.Id = groups.ItemId
where row_num = 1
order by I.Rating desc
OFFSET {(@page - 1) * count} ROWS FETCH NEXT {@count} ROWS ONLY";Answer the question
In order to leave comments, you need to log in
1. The appearance of duplicates in the table is better to exclude in principle, and not to clean up after the fact. In general, this will create a more even distribution of data across database blocks and have a positive effect on overall performance. If some application "produces" duplicates, which you cannot influence, then consider using triggers on the AccountItems table.
2. As a result of the implementation of paragraph 1. Your request will become easier. And if you also look at the query plan, add the necessary indexes, break AccountItems into partitions, then there is a chance to do it very well.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question