Answer the question
In order to leave comments, you need to log in
How to log in with a parser on the site?
Help, I'm new to Python, I'm parsing the site based on this tutorial: https://www.youtube.com/watch?v=kO8AHedGh8o
My task is to get information from the site with authorization, I got the following code:
import requests
from bs4 import BeautifulSoup
class Bars(object):
url = 'ссылка на сайт'
def auth(self):
url = self.url+'/auth/login'
session = requests.Session()
params = {
'login_login':u'мой логин',
'login_password':u'мой пароль'
}
r = session.post(url,params)
print(r.text)
if __name__ == '__main__':
bars = Bars()
bars.auth()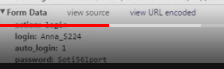
https://qna.habr.com/
Answer the question
In order to leave comments, you need to log in
Well, like xs what kind of site you have there, but you can almost always do authorization and parse.
Here is the algorithm of actions:
1) Create an acc (preferably manually, because there can be all sorts of different captchas, etc.)
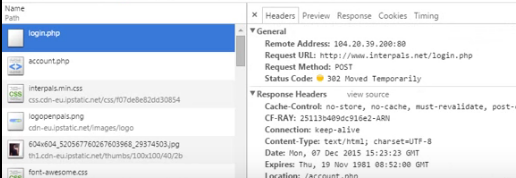
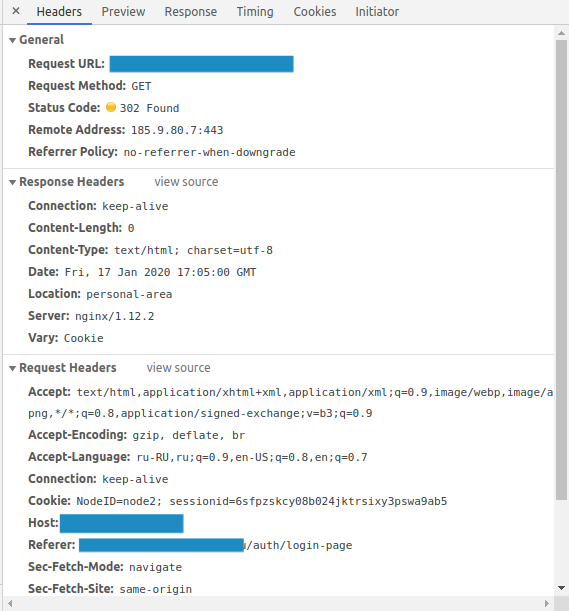
2) Log in again manually and simultaneously look at the Network tab in the debugger of the browser. May fail if the page is reloaded. Then you go to the authorization form and look at the field names and the request handler. It might not work out that way either. Then download some tool for debugging the site so that the page does not reload and you can see the request.
3) Create a session in python and make a request. In the future, you constantly send requests only through the session, because it's almost like a browser (session stores cookies and other crap)
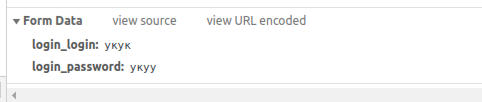
authdata = {'login': 'mylogin', 'password': 'mypassword'}
mysession = requests.session()
response = mysession.post('https://example.com/reg.php', data=authdata)
parsedata = mysession.post('https://example.com/catalog') //тут я делаю парсинг через сессию страницы каталога сайта, ты вписываешь свою страницу, которую хочешь спарситьDidn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question