Answer the question
In order to leave comments, you need to log in
How to implement a similarity search for two strings (product names)?
Good afternoon.
I'm thinking about the following task: there are products in the database and there are price lists, I want to implement at least some auto-mapping of a product from the database to a product from the price list.
For example, in the database there is a product: "Apple Macbook Pro 15" and in the price list "Apple Macbook Pro 15", "Apple Macbook Pro 14", you need to link Apple Macbook Pro 15 from the database and Apple Macbook Pro 15 from the price list.
What I tried:
1. MySQL full-text search, but it returns both Apple Macbook Pro 15 and Apple Macbook Pro 14 with the same relevance.
2. Jaro-Winkler distance. Here did the following:
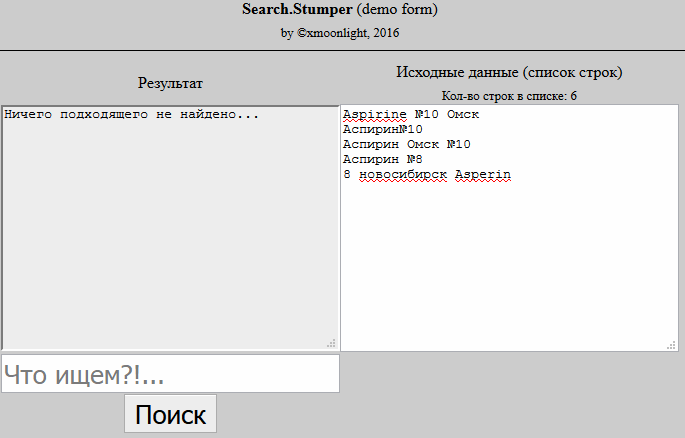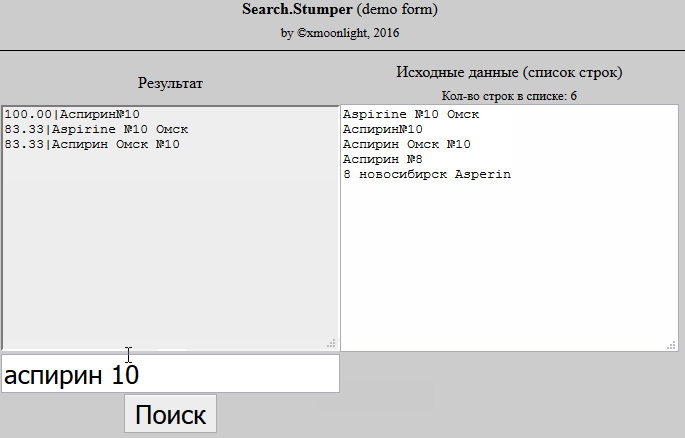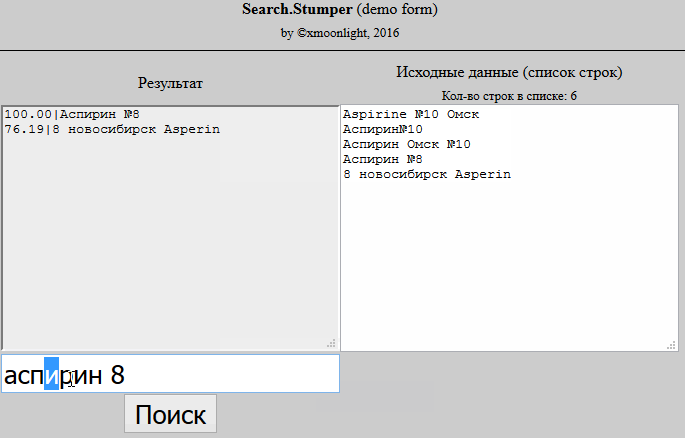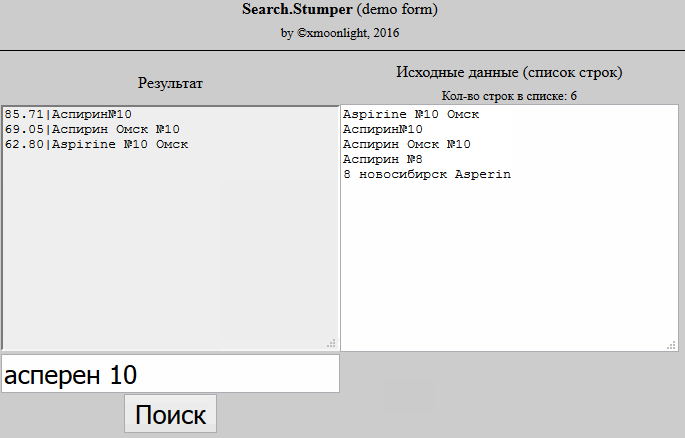
I take a product from the database and break its name into words, I get an array. I do the same with the name from the price list. I start to go through an array of product words from the database and look for a distance for it using the Jaro-Winkler algorithm in an array of product words from the price list, if I find a distance greater than 0.95, I note that for this word the corresponding word from the product was found in the price list. Then I see that for each word of the product from the database, the corresponding word from the product in the price list was found and I consider them the same.
But an acceptable result did not come out of this. If, for example, I have the product "Apple Macbook Pro 15", and in the price list "Apple Macbook Pro 15 the bag is blue", then according to the second point that I described above, the similarity will be 100%, but these are completely different products.
I don’t even know where to dig, maybe someone came across a similar one? Advise any algorithms please.
Answer the question
In order to leave comments, you need to log in
1. MySQL full-text search, but it returns Apple Macbook Pro 15 and Apple Macbook Pro 14 with the same relevance.It's even good, I would say. With the same similarity (ranking) we refer to the same group.
The Tomita parser is designed to extract structured data from natural language text. Extraction of facts occurs with the help of context-free grammars and keyword dictionaries. The parser allows you to write your own grammars and add dictionaries for the desired language. The source code of the project is open and posted on GitHub.
This topic is called "fuzzy search" or "error-tolerant search" or as Fuzzy Search was said earlier.
There are two aspects here: what to look for (technology) and how exactly to look for (approach, methodology).
1) If you have little data and it fits easily into memory, then do a search by the inverted index in memory.
Otherwise, use a search index, suggesting solr, elasticsearch or pure lucene .
2) Tuning through one of the similarity coefficients. I would advise the Sorensen coefficient ( https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D1%8D%D... ) or its inverse Dice measure. Levenshtein distance, because this edit distance resolves much more slowly.
Basic steps:
1) Data cleaning and indexing.
2) Search query and ranking by relevance.
You can also add this option:
https://www.postgresql.org/docs/9.1/static/pgtrgm.html
F.35.1. Trigram (or Trigraph) Concepts
A trigram is a group of three consecutive characters taken from a string. We can measure the similarity of two strings by counting the number of trigrams they share. This simple idea turns out to be very effective for measuring the similarity of words in many natural languages.
An honest comparison with a 100% guarantee can only be done by a person. since one analysis of letters / words is not enough, an analysis by meaning is needed.
I doubt that you are ready to write AI there. try, in addition to the name, to take into account the coincidence of the price within certain limits (or other attributes), then the macbook and the bag will be separate at least.
I can also suggest hardcoding the names of accessories ("bag", "case", etc.), if the subject matter of the goods is more or less final. it will solve most of the problems.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question