Answer the question
In order to leave comments, you need to log in
How to go to the internal link of the site and parse data from there?
I need to take the product cards of the site (price, photos, description, etc.) to pick up all the product cards, I must connect to the site (I did). Now the question is how do I go through all the links of the site and take only the product information? I watched how recursion works, but I just can’t figure out how to take only product cards
, my code
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class readAllLinks {
public static Set<String> uniqueURL = new HashSet<String>();
public static String my_site;
public static void main(String[] args) {
readAllLinks obj = new readAllLinks();
my_site = "al-style.kz";
obj.get_links("https://al-style.kz/");
}
private void get_links(String url) {
try {
Document doc = Jsoup.connect(url).userAgent("Mozilla").get();
Elements links = doc.select("a");
if (links.isEmpty()) {
return;
}
links.stream().map((link) -> link.attr("abs:href")).forEachOrdered((this_url) -> {
boolean add = uniqueURL.add(this_url);
if (add && this_url.contains(my_site)) {
System.out.println(this_url);
get_links(this_url);
}
});
} catch (IOException ex) {
}
}
}Answer the question
In order to leave comments, you need to log in
public class readAllLinks {
Class names must begin with a capital letter. Read about name convention
As for your code, there are many nuances.
I need to take the product cards of the site (price, photos, description, etc.) to pick up all the product cards I have to connect to the site (I did)
Elements links = doc.select("a");Now the question is how do I follow all the links of the site and take only the information of the product?
#categories .sub-menu-item .sub-menu-linkdoc = Jsoup.connect(url).userAgent("Mozilla").get();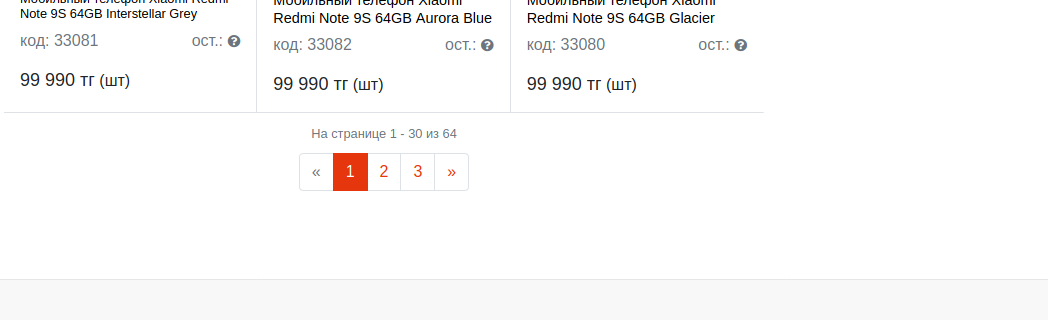
https://al-style.kz/catalog/mobilnye_telefony/
https://al-style.kz/catalog/mobilnye_telefony/?PAGEN_1=2
?PAGEN_1={pageNum}.elements .element
.elements .element .linkDidn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question