Answer the question
In order to leave comments, you need to log in
How to get the site encoding?
BufferedReader body = new BufferedReader(new InputStreamReader(con.getInputStream(), "utf-8");
String tempLine, outString = "";
while ((tempLine = body.readLine()) != null)
outString += tempLine + " ";
body.close();
return outString;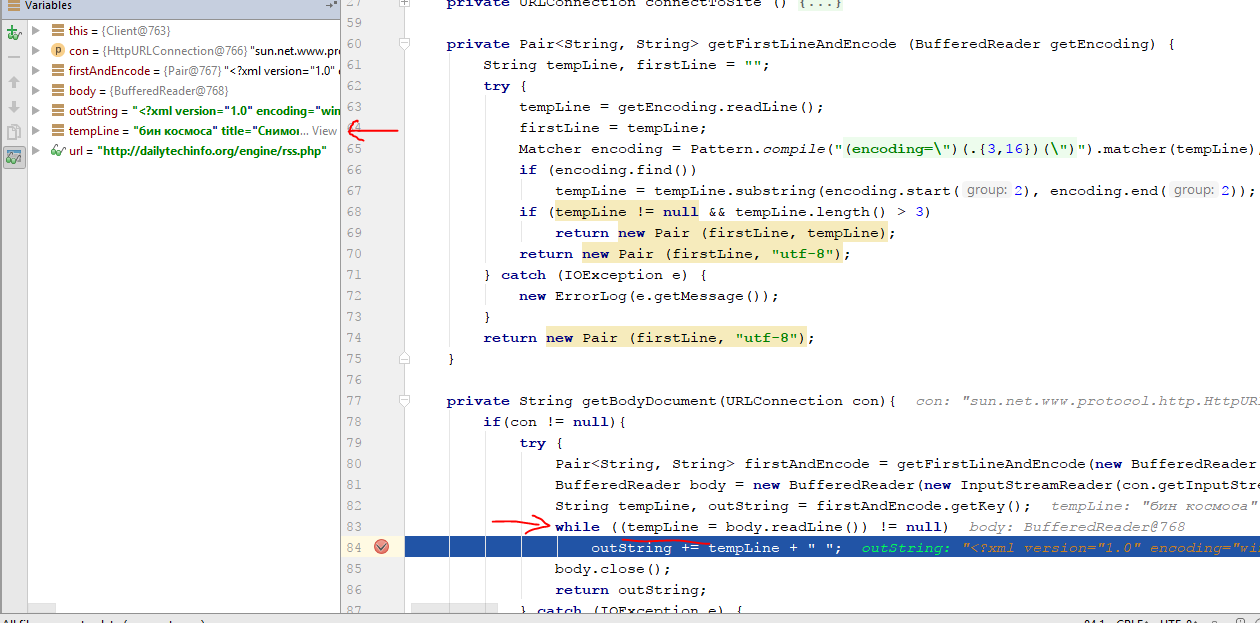
Answer the question
In order to leave comments, you need to log in
The moment you receive a string, it is already stored in Java UTF-16 anyway. That is why the encoding is specified for the reader before reading begins.
With an already read line, if it was read in the wrong encoding and "corrupted", and the encoding is still unknown, nothing can be done.
In order to determine the source encoding of the site you are uploading, you must first get it not as a string, but as an array of bytes . After that, you can work with it and already determine the encoding either with the help of your crutches, or already existing strangers .
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question