Answer the question
In order to leave comments, you need to log in
How to get page code?
I'm doing facebook parsing and I've run into a problem. If I look at the page's code, I see a beautiful html tree broken into blocks, etc. But, when I get soup, I get, as it seems to me, obfuscated page code. If you have come across this, what have you done, or perhaps you have some good sources where you can read about obfuscation in a more understandable way for a beginner. I will be glad to everything. Sample code where I get soup.
if not self.browser.is_free():
self.browser.driver.get(url)
# js_code = "document.getElementsByTagName('html')[0].outerHTML"
# your_elements = self.browser.driver.execute_script(js_code)
html = self.browser.driver.page_source
soup = BeautifulSoup(html, 'html.parser')
return soup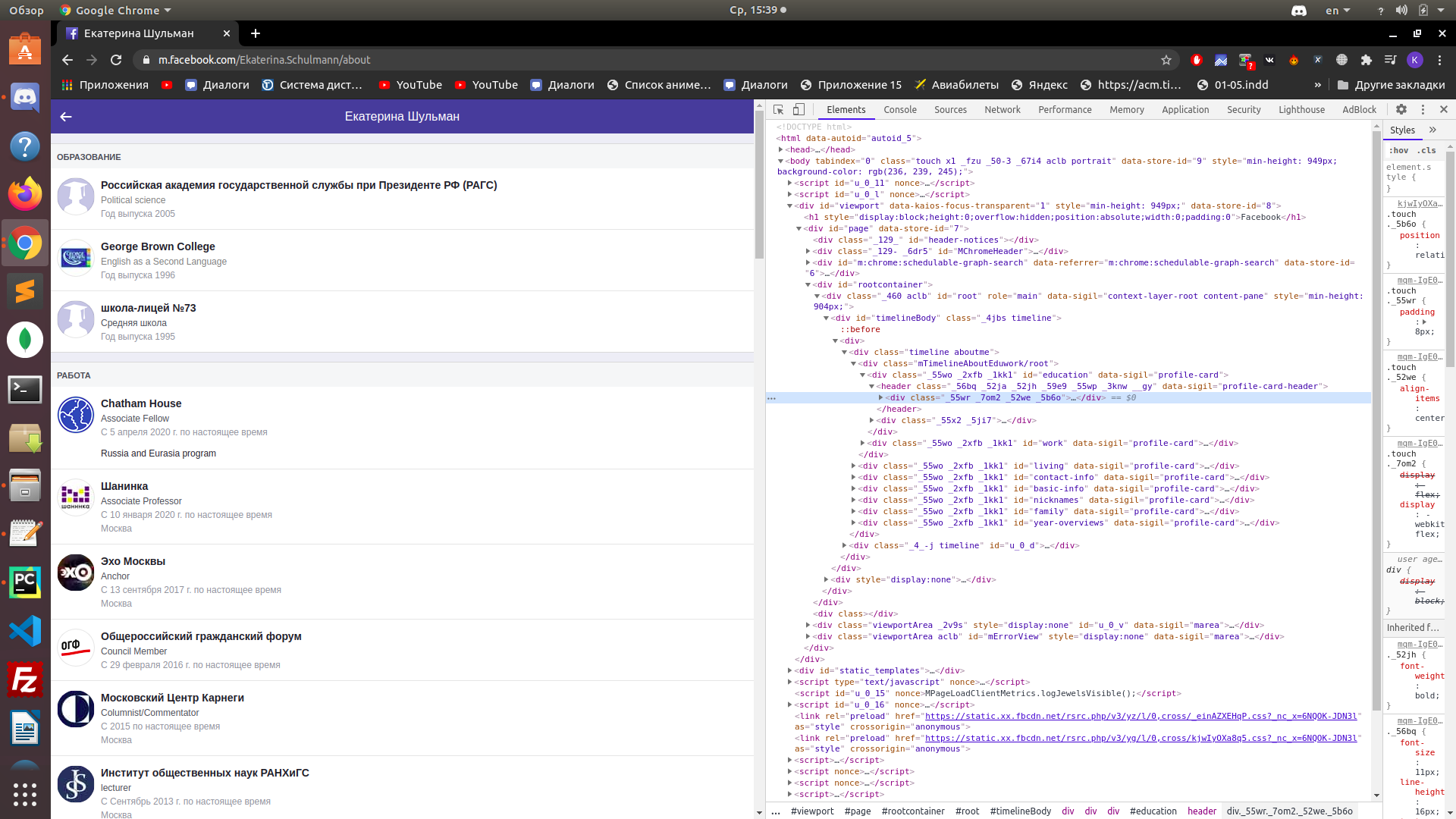
Answer the question
In order to leave comments, you need to log in
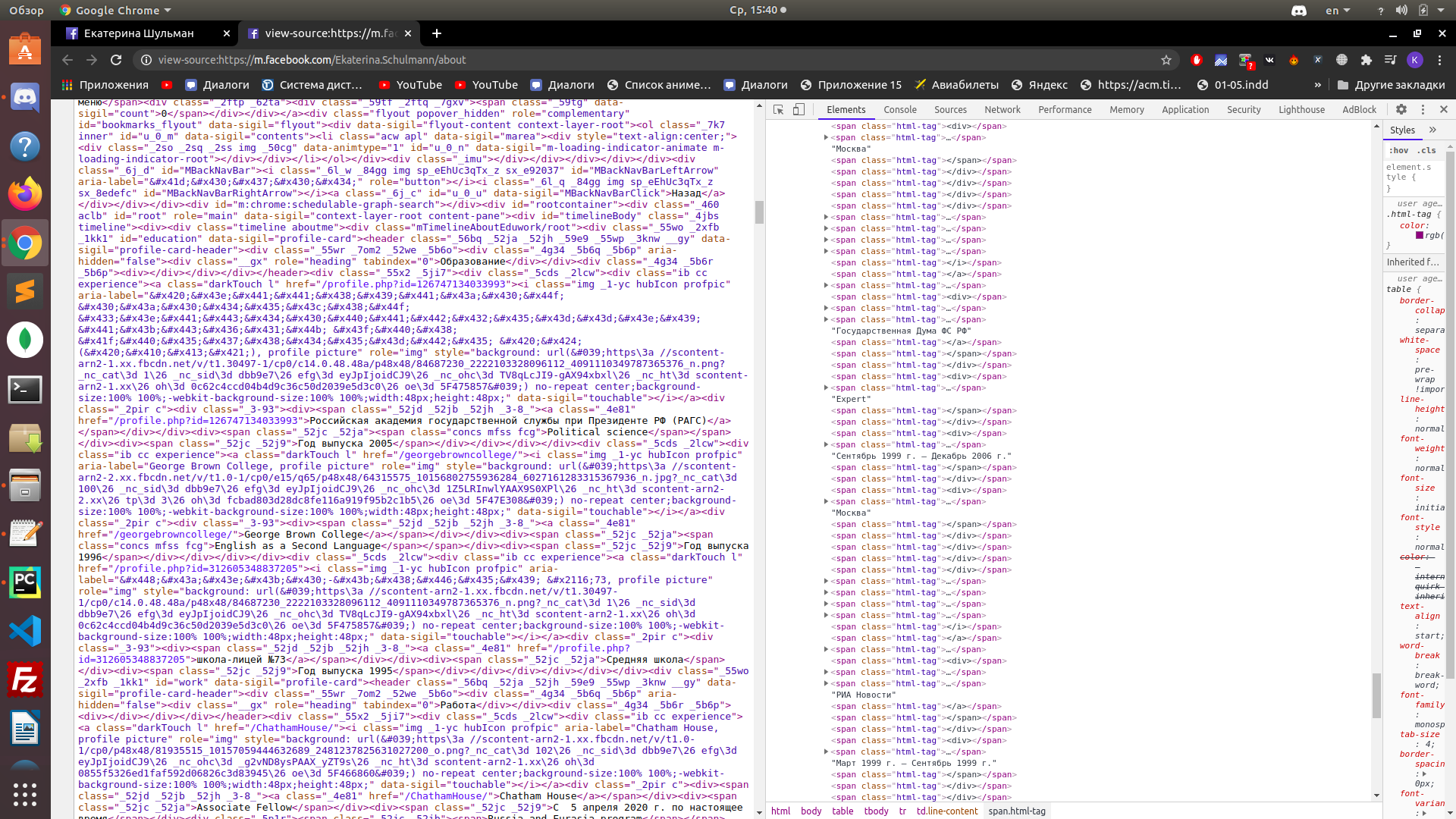
When you look in devtools, you see the DOM built by the browser. The browser parsed as best it could, corrected the errors that it could, brought it to a beautiful view. When you look at the source code (ctrl+U in the browser), you see what actually came from the server.
HTML entities are not hard to decode
import html
x = html.unescape('Эхо Москвы')
print(x) # -> эхо москвыSo I don't understand what the problem is.
In F12-> Elements you see the page code rendered by a JS script
In Ctrl+U you can see the source code, without JS processing
In the source code, the tree is not built because Facebook decided so, the code is not intended for human reading, the computer understands it and in a minimized form .
Or you type encoding
Эхо МосквыDidn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question