Answer the question
In order to leave comments, you need to log in
How to get data from a dynamic site (Python, BeautifulSoup, Selenium)?
Good day to all! Thanks in advance for your replies.
There is a site that displays dynamic content: https://www.tradingview.com/chart/mTxoGgAC/
Using Beautiful Soup, I can get any values \u200b\u200bwithout problems, as long as they are displayed in html.
In this case, the site (if I understand correctly) outputs scripts, which in turn already output content to the browser in html. And naturally, with Beautiful Soup, I can't get the content I want.
What are the ways to get data from such sites?
For example, I need to get data from this block:
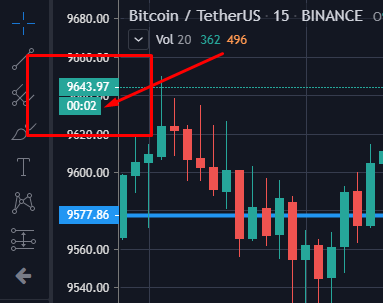
Tell me in which direction to dig and whether it is generally feasible in general.
Thank you!
Answer the question
In order to leave comments, you need to log in
In the browser console, in the Network tab, examine the POST / GET requests responsible for loading content and repeat them on your server.
They have some kind of API https://www.tradingview.com/rest-api-spec/ can help
. They seem to take the data you are interested in from binance. Binance definitely has an API
Selenium handles this without any problem, what's strange is that you mentioned it in the question but didn't try it
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question