Answer the question
In order to leave comments, you need to log in
How to find downloaded files?
Hello!
There is a site from which you need to extract financial reporting data, for example , here is the link
Reporting files in Excel format are downloaded from this page by clicking on the button, which is a link to the corresponding part of the file archive. Screenshot of the page and element code: 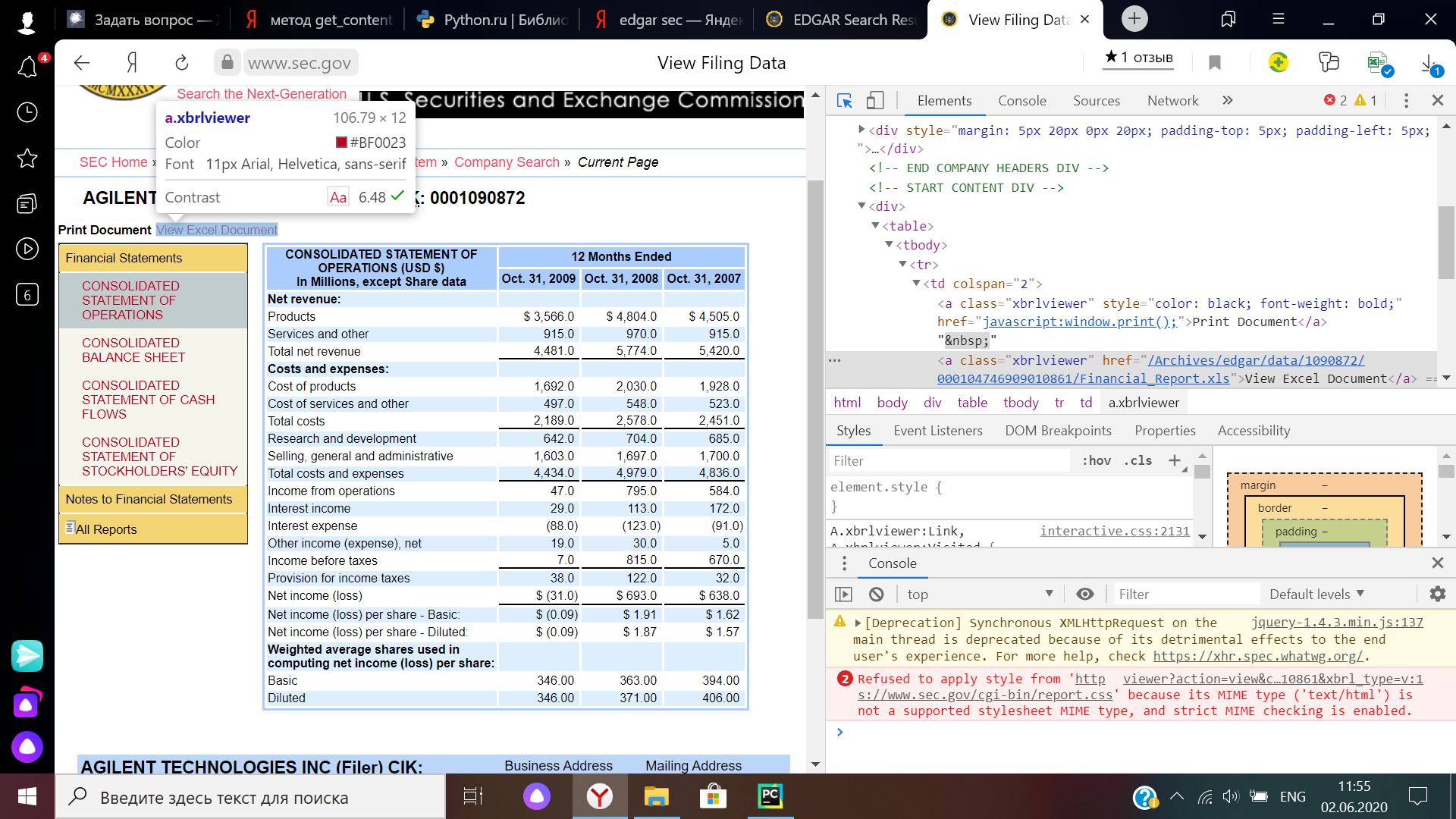
Wrote a code that generates the necessary download links and accesses the site using them
import requests
from bs4 import BeautifulSoup
import re
from time import sleep
import urllib.request, urllib.parse, urllib.error
# парсинг на примере Agilent Technologies, Inc.
url = 'https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=A&type=10-K&dateb=&owner=exclude&count=40'
user_agent = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 YaBrowser/20.4.3.257 Yowser/2.5 Yptp/1.23 Safari/537.36'}
res = requests.get(url, headers=user_agent).text
soup = BeautifulSoup(res, 'lxml')
CIK_data = soup.find('span', class_='companyName').find('a').get_text()
CIK_num = re.findall(r'\d+',CIK_data)
CIK = CIK_num[0].lstrip('0')
print('CIK: ',CIK)
Acc_no_data = soup.find_all('tr')[3:]
# print(Acc_no_data)
for elem in Acc_no_data:
sleep(40)
Acc_no = re.findall(r'\d+', elem.find('td', class_='small').text.replace('-',''))[3]
# print(Acc_no)
date = elem.find_all('td')[3].text
get_file = requests.get(f'https://www.sec.gov/Archives/edgar/data/{CIK}/{Acc_no}/Financial_Report.xlsx', headers=user_agent)Answer the question
In order to leave comments, you need to log in
It doesn't work that way a little. Make a request to the desired URL, you get the information in bytes. Then you just need to open a record to a file by selecting the WB (Write-Bytes) mode, and simply write the information received from the link, which is available in r.content
import requests
url = 'https://www.sec.gov/Archives/edgar/data/1090872/000104746909010861/Financial_Report.xls'
r = requests.get(url)
with open('report.xls', 'wb') as f:
f.write(r.content)Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question