Answer the question
In order to leave comments, you need to log in
How to extract tabular data from html?
I am learning to write parsers. Now my task is to parse tabular data from the site https://coinmarketcap.com/ , where I directly need data from the table of cryptocurrencies, their cost, etc., which are in the tbody block.
But when using Beautiful Soup I try to get into the table, into the tbody object, it gives out "AttributeError: 'NoneType' object has no attribute 'find_all'". At the same time, he sees the thead object perfectly and there are no errors. How can I still ensure that the program sees this block of the site?
I have already tried all possible permutations of the code, some replacements in the elements, but nothing helps, and the program still does not see the body of the table.
import requests
from bs4 import BeautifulSoup
import csv
def get_html(url):
r = requests.get(url)
return r.text
def write_csv(data):
with open('cmc.csv', 'a') as f:
writer = csv.writer(f)
pass
def get_page_data(html):
soup = BeautifulSoup(html, 'lxml')
trs = soup.find('table').find('tbody').find_all('tr')
print(len(trs))
def main():
url = 'https://coinmarketcap.com/'
get_page_data(get_html(url))
if __name__ == '__main__':
main()
Answer the question
In order to leave comments, you need to log in
I riveted on a quick hand. Not the fact that the code is correct, but working:
import requests
from bs4 import BeautifulSoup
url = 'https://coinmarketcap.com/'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'lxml')
all = soup.find_all('',class_='cmc-table-row')
for x in all:
rank = x.find('td',class_='cmc-table__cell--sort-by__rank').text
name = x.find('td',class_='cmc-table__cell--sort-by__name').text
market_cap = x.find('td',class_='cmc-table__cell--sort-by__market-cap').text
price = x.find('td',class_='cmc-table__cell--sort-by__price').text
volume = x.find('td',class_='cmc-table__cell--sort-by__volume-24-h').text
circulating_supply = x.find('td',class_='cmc-table__cell--sort-by__circulating-supply').text
change = x.find('td',class_='cmc-table__cell--sort-by__percent-change-24-h').text
print(f'{rank} {name} {market_cap} {price} {volume} {circulating_supply} {change}')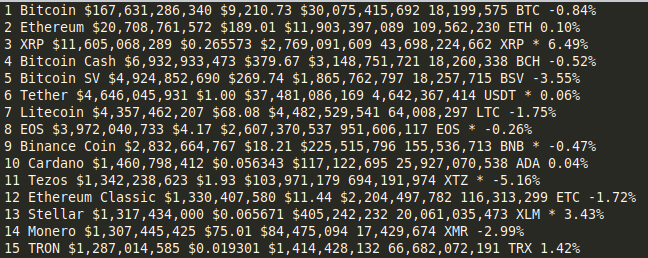
import requests
from bs4 import BeautifulSoup
url = 'https://coinmarketcap.com/'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'lxml')
all = soup.find_all('',class_='cmc-table-row')
for x in all:
rank = x.find('td',class_='rc-table-cell table-col-rank rc-table-cell-fix-left').text
name = x.find('a',class_='cmc-link').find('p').text
market_cap = x.find('td',class_='rc-table-cell font_weight_500___2Lmmi').text
price = x.find('td',class_='rc-table-cell font_weight_500___2Lmmi').text
volume = x.find('div',class_='Box-sc-16r8icm-0 sc-1anvaoh-0 gxonsA').a.p.text
circulating_supply = x.find('p',class_='Text-sc-1eb5slv-0 kqPMfR').text
# change = x.find('td',class_='cmc-table__cell--sort-by__percent-change-24-h').text
print(f'{rank} {name} {market_cap} {price} {volume} {circulating_supply}')Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question