Answer the question
In order to leave comments, you need to log in
How to discard outliers from the stream of similar ones (input data filtering)?
there is such an input stream: 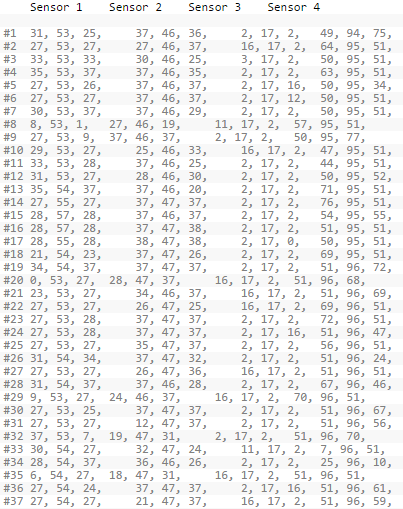
How can you extract from this the two most occurring numbers out of three, for each sensor?
Those. in this case, get the triples [*, 53, 27], [*, 46, 37], [2, 17 *], [*, 95, 51].
Now the arithmetic mean is used, but due to random bursts, the deviation from the "standard" is more than 3 units, which is not satisfactory: it turns out [25, 53, 25], [32, 46, 33], [5, 17, 4], [54, 95, 52].
Roughly speaking, out of 200 numbers in each column, it is necessary to discard obviously random bursts that are very different from the rest, then find for each column the number with the maximum frequency of occurrence (plus or minus the allowable error) and select the two most frequently occurring numbers from each triple.
What are these algorithms called? In particular, with the C++ language.
Answer the question
In order to leave comments, you need to log in
I can offer a stupid solution.
Accumulate the number of occurring numbers, for example, instd::map<int, std::size_t>
std::map<int, std::size_t> m;
for (int v : vals) { ++m[v]; }
std::vector<std::pair<int, std::size_t> > v(m.begin(), m.end());
std::sort(v.begin(), v.end(), [] (std::pair<int, std::size_t> const & l, std::pair<int, std::size_t> const & r) { return l.second > r.second; });
// в v пары "число - кол-во таких чисел", отсортированы по убыванию
// можно откинуть нижнюю часть (те, которые встречаются реже, чем какой-то процент, например, 10%)
v.erase(
std::find_if(v.begin(), v.end(), [] (std::pair<int, std::size_t> const & x) { return x.second < (v.size() / 10); }),
v.end());
// а сверху взять часто встречающиеся
int row_value = v.front().first;Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question