Answer the question
In order to leave comments, you need to log in
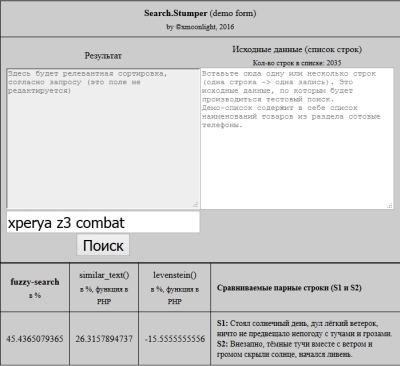
How to determine the similarity of two strings?
Greetings.
I ask for your help in solving the problem. Prompt the direction where to "dig".
There is a list of strings. Line length 2-7 words. These lines contain the names of various applications. Lines are often misspelled, have extra words, or are shorter than the original title.
For example, "Program Document System" instead of "Program Plus Documents".
That is, in these lines a certain essence of the correct name is preserved.
There is a database (list) of correct program names.
It is necessary to check two lists in order to understand whether there are the desired strings in the database, if so, how they are correctly called, if not in the database, then understand this.
Verbatim comparison will not work, because the search strings are people,
Thought about checking strings for "similarity". This is where it stalled.
There is a check of words for similarity through fuzzy search algorithms. It's not entirely clear which is better.
I do not fully understand how to understand that a whole sentence (a set of words) is similar to another sentence.
Please help with advice. I do not expect ready-made solutions (unless something similar for an example). Tell me where to "dig", how to build an algorithm?
I will implement in Java.
UPD: I came across a topic where a fuzzy comparison algorithm was used to compare words from a sentence with a dictionary of correct words.
We indexed the sentence, built an array of occurring words and links with other words. I will not explain further, I do not quite understand.
What is indexing? How does it help in finding the whole sentence for individual words.
Thanks to those who responded ☺
Answer the question
In order to leave comments, you need to log in
Choose a fuzzy comparison algorithm, try it. Approached - well, no - look further.
It's funny, but literally just now an article on a related topic was published on Habré: https://habrahabr.ru/post/275937/
The TS needs something like a plagiarism search system
https://habrahabr.ru/post/199190/
you can take the Sphinx, add a stemmer, add synonyms and then see how the relevance
sphinxsearch.com/blog/2010/08/17/ will work how-sphinx-releva...
I came to the conclusion that it would be good to master Apache Lucene.
The search method that I had self-made worked "not so very well".
A lot of "finishing" was required for various inaccuracies.
But. There are a couple of "buts". The creation of a self-made product allowed us to study in more detail the issue of search, search engines, splitting into tokens and indexing.
So everything was great.
Try your ideas. Even if it doesn't work, gain experience.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question