Answer the question
In order to leave comments, you need to log in
How to correctly remove duplicate rows/links in a database?
Good afternoon, please tell me how to solve my problem more competently.
I have 5+ tables describing, as it were, an inventory of the computer park on the network. The information in the tables comes from a third-party program at different intervals, I can’t control the insertion process, I can only do something with the information already available. This first REPORT
table new rows are inserted into it from time to time, i. each new line, this is a new report created.
The second is CPU - a table of processors used in the computer park of the network (the values are unique)
And the third CPU_RELATION_REPORT - a table for organizing many-to-many communication between REPORT and CPU
And similarly, tables 4 and 5 simply describe the MOTHERBOARD
Below in the screenshot, I cited my problem, namely, that reports are taken from computers every time they are turned on, and it turns out that the change of components is a rather rare phenomenon, and as a result of which very there are a lot of repetitive links and reports as such, but there is no point in storing them.
So the question is, how to get rid of such correctly, what kind of tricky query should be made that will find the rows of reports that have the same links with the CPU tables, MOTHERBOARD , ... (there are actually 10 or more such lookup tables) compared to the previous row in the context of one HOST and delete them.
Those. According to the screenshot below, you need to delete the first line from REPORT and the first lines from CPU_RELATION_REPORT, MOTHERBOARD_RELATION_REPORT - thus leaving the most recent and up-to-date.
Those. you need to somehow cunningly unique combinations of links and reports, getting rid of duplicates 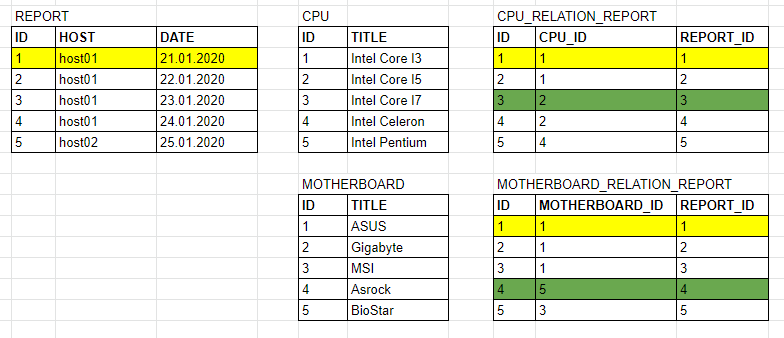
p.s. and I must admit that further my task is even more difficult, there are such connections that still have additional attributes, i.e. another table is connected to the ..._RELATION_... table that describes some variables of this particular connection - and it turns out that you also need to look at the uniqueness not only in the context of REPORT -> RELATION -> CPU, but also the values of an additional table connected to RELATION
Answer the question
In order to leave comments, you need to log in
start with this
, it’s also easier to transfer all this unique to new tables, and let these swell and archive annually
Depends on the value of this information. If this scheme is considered as history, then nothing needs to be deleted. Just rewrite your reports so they do GROUP BY and DISTINCT and just ignore duplicates.
If you are the owner of this system and data, then you have the right to set any uniqueness constraint so that it is basically impossible to put a duplicate. But this is not a technical issue, but an organizational one.
Delete - there are many advisers. But all of them are irresponsible, and if you don't listen to advice on cleaning data right here in the toaster, then you run the risk of losing the necessary data.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question