Answer the question
In order to leave comments, you need to log in
How to concisely write a set of aggregate functions with conditions in pandas?
Hey!
Sample data:
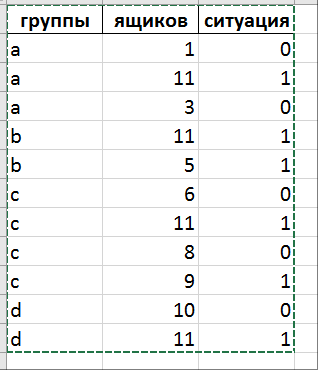
df = pandas.DataFrame()
df['группы'] = ['a','a','a','b','b','c','c','c','c','d','d']
df['ящиков'] = [1,11,3,11,5,6,11,8,9,10,11]
df['ситуация'] = [0,1,0,1,1,0,1,0,1,0,1]
dfSELECT
"группы",
COUNT(DISTINCT CASE WHEN "ситуация" = 1 THEN "ящиков" END) AS "уникальных_ящиков_при_ситуации_1",
SUM(CASE WHEN "ситуация" = 0 THEN "ящиков" END) AS "сумма_ящиков_при_ситуации_0",
..
..
GROUP BY "группы"Answer the question
In order to leave comments, you need to log in
Maybe something like this? I'm quite fluent in SQL and I'm not sure what it will give out in the end ...
import pandas
df = pandas.DataFrame()
df['группы'] = ['a', 'a', 'a', 'b', 'b', 'c', 'c', 'c', 'c', 'd', 'd']
df['ящиков'] = [1, 11, 3, 11, 5, 6, 11, 8, 9, 10, 11]
df['ситуация'] = [0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1]
print(df[df['ситуация'] == 1].groupby('группы').count())
print(df[df['ситуация'] == 0].groupby('группы').sum())Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question