Answer the question
In order to leave comments, you need to log in
How to build a regression on string data (machine learning)?
Regression algorithms work with characteristics data represented as numbers. For example: It is 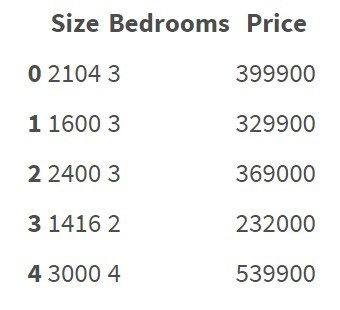
pretty clear how to build a regression model on this data and predict the price.
But for now, I'd like to build a regression model on data that contains strings (string type):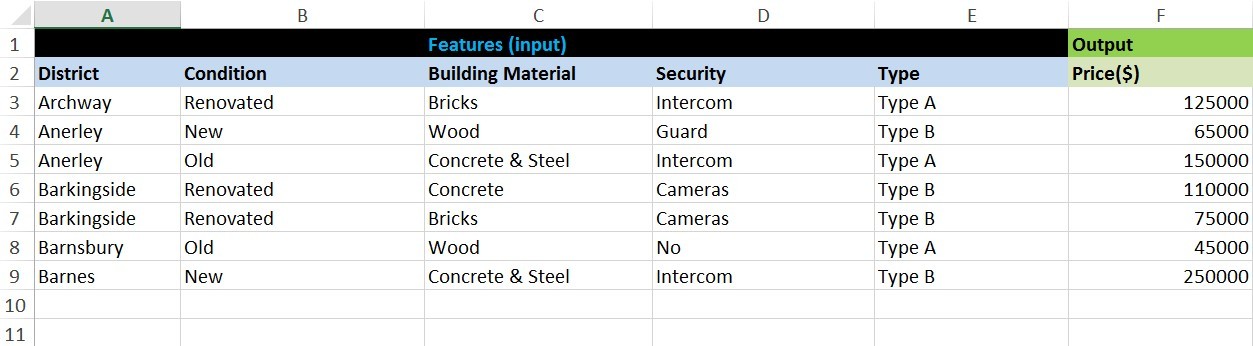
How to build a regression on such data? Should I convert this string data to numbers manually? I mean, should I create any encoding rules myself, and according to these rules, convert all data to a numerical format? Is there a more or less simple way to convert string data to a numerical format without having to create your own encoding rules, and convert the data manually. Are there any Python libraries that can help with this routine? Are there risks that the regression model will be incorrect to some extent due to "bad conversion" to a numerical format?
Answer the question
In order to leave comments, you need to log in
You can try to do the following. We take each column, in fact a category. Let's see how many values it has. Let it be k. We start k variables that will take values either 0 or 1.
If, say, the house was built of brick, then we set the variable x_brick = 1, and x_concrete and x_wood equal to 0. Well, we train the weights.
PS You can make k - 1 variable by putting zeros in all variables for one of the values.
I suspect that some decision tree algorithms can do what you need.
If I remember correctly, then most likely CART , but most likely not only him.
In python, look at the libraries scikit , spark , but I did not have to use them.
Just in case, I know for sure that this and many other tree algorithms are in WEKA (a separate program for data mining with its own formats, etc.).
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question