Answer the question
In order to leave comments, you need to log in
Does not cling to tags, class. The first request for HTML does not return all the code, the body tag remains hidden, how to get there and is this the problem?
Good morning everybody! Faced such a task: you need to ask the site for information, when trying to cling to tags and classes, it gives out exactly zero. If you make the first request to the html page or save the site page in html, you find that the page comes to the whole, everything that is hidden in the body tag, maybe this is the problem, if so, how to solve it? Site: https://www.whitegoods.ru/
First I need to grab the link to the category and the name of this category
Code:
from cgitb import html
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
head = {
"Accept": "*/ *",
"User-Agent": 'UserAgent().random'
}
url = " https://www."
def get_html(url, params = ''):
r = requests.get(url, headers = head)
return r
def get_content(html):
soup = BeautifulSoup(html, 'html.parser')
items = soup.find( 'a', class_= 'maincat__title')
print(items)
def parse():
html = get_html(url)
get_content(html.text)
print(html.text)
parse()
What am I doing wrong?
Answer the question
In order to leave comments, you need to log in
There is a documentation for beautifullsoup  , but I don’t understand where to apply it, after trying
, but I don’t understand where to apply it, after trying 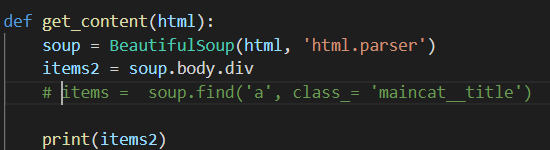 , the response is not a full html page
, the response is not a full html page
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question