Answer the question
In order to leave comments, you need to log in
Could there be a problem in robots.txt when a site is crawled by a search engine?
Two weeks ago I added a site to Google, after searching the search I came across an article that describes what needs to be checked where, for example, "checking optimization for mobile devices", I checked it and it gave me such a result
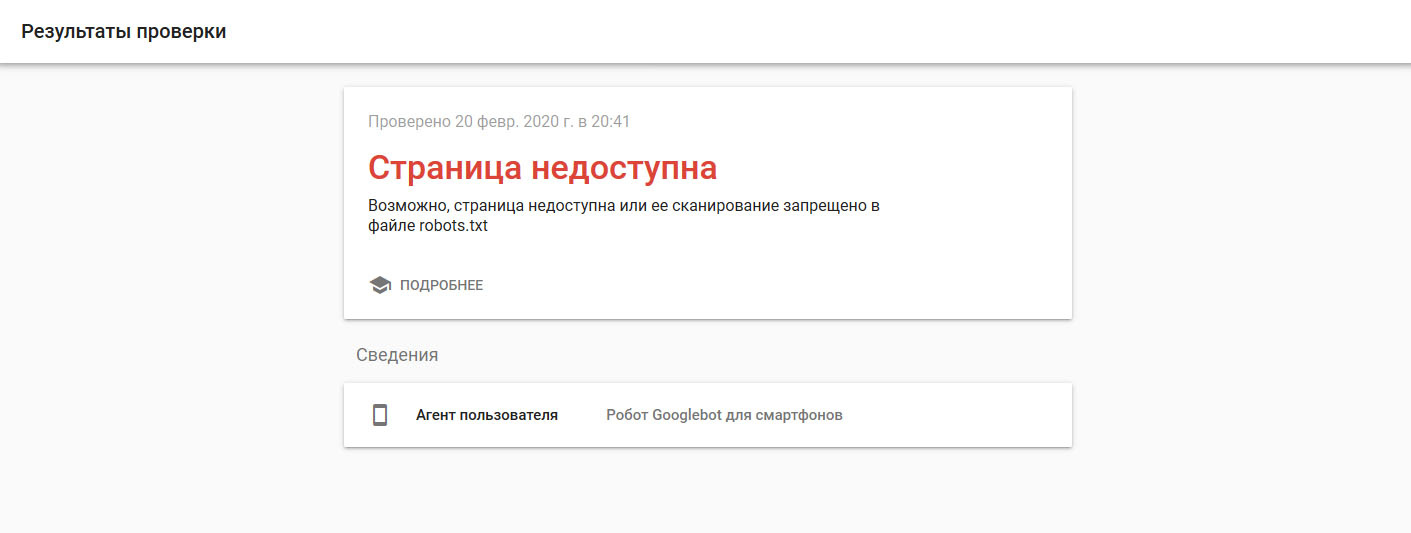
. robots.txt itself looks like this
User-agent: *
Disallow:
Host: https://.............
Sitemap: https://............./sitemap.xml
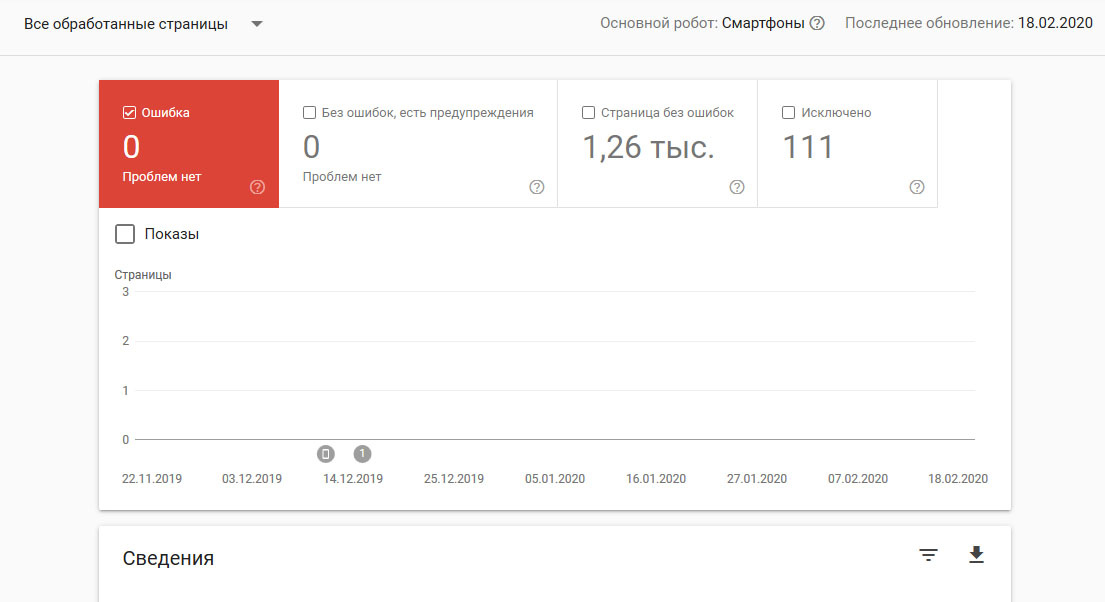
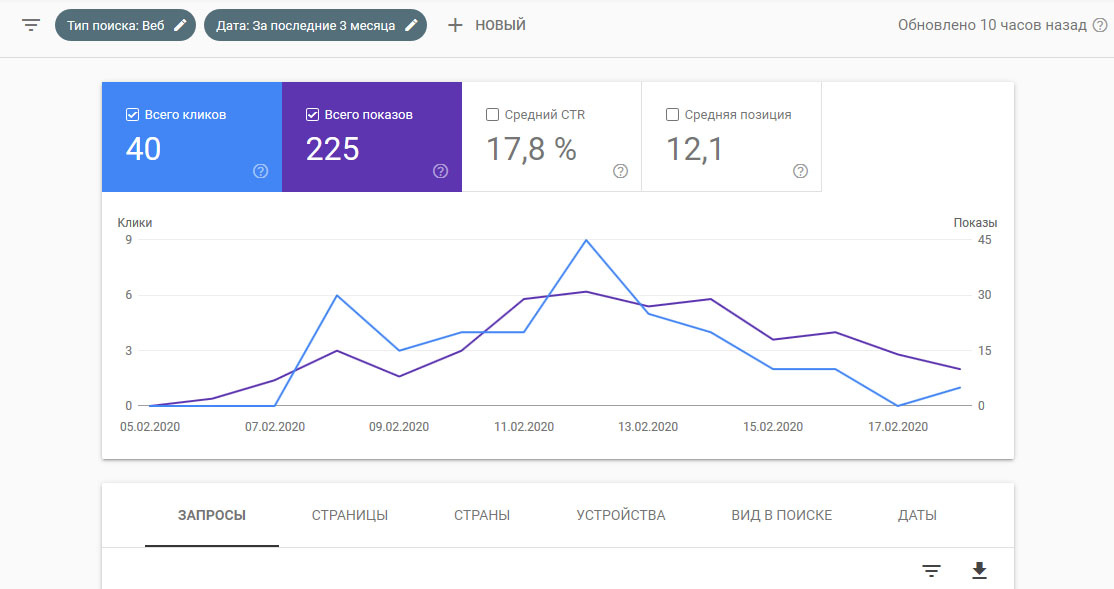
Answer the question
In order to leave comments, you need to log in
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question