Answer the question
In order to leave comments, you need to log in
Can't get link from href using python?
>I can't parse the link in href
Program code:
import requests
from bs4 import BeautifulSoup
URL = 'https://zaka-zaka.com/'
HEADERS = {
'user-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36',
'accept': '*/*'}
def get_html(url, params=None):
r = requests.get(url, headers=HEADERS, params=params)
return r
def get_content(html):
soup = BeautifulSoup(html, 'html.parser')
items = soup.find_all('a' , class_='game-block')
games = []
for item in items:
games.append({
'title': item.find('div' , class_='game-block-name').get_text(strip=True),
'link': item.find('a', class_='game-block') .get('href')
})
print(games)
def parse():
html = get_html(URL)
if html.status_code == 200:
get_content(html.text)
else:
print('Error')
print(html)
parse()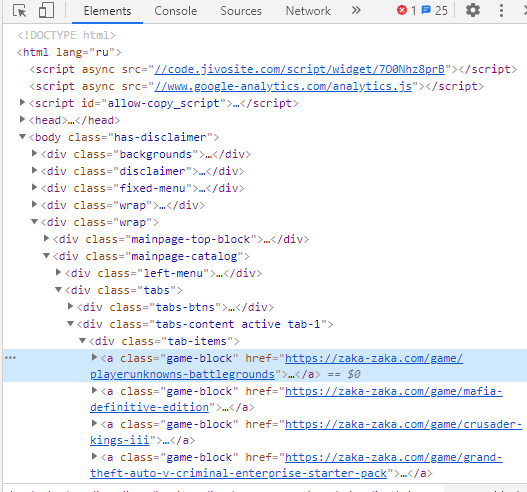
Answer the question
In order to leave comments, you need to log in
import requests
from bs4 import BeautifulSoup
URL = 'https://zaka-zaka.com/'
HEADERS = {'user-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36','accept': '*/*'}
def get_html(url, params=None):
r = requests.get(url, headers=HEADERS, params=params)
return r
def get_content(html):
soup = BeautifulSoup(html, 'html.parser')
items = soup.find_all("a", {'class': 'game-block'})
games = []
for item in items:
href = item.get('href')
title = item.find('div', {'class': 'game-block-name'}).get_text(strip=True)
games.append({'title': title, 'link': href})
print(games)
def parse():
html = get_html(URL)
if html.status_code == 200:
get_content(html.text)
else:
print('Error')
print(html)
parse()Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question